Abstract
Recently, text-guided 3D generative methods have made remarkable advancements in producing high-quality textures and geometry, capitalizing on the proliferation of large vision-language and image diffusion models. However, existing methods still struggle to create high-fidelity 3D head avatars in two aspects: (1) They rely mostly on a pre-trained text-to-image diffusion model whilst missing the necessary 3D awareness and head priors. This makes them prone to inconsistency and geometric distortions in the generated avatars. (2) They fall short in fine-grained editing. This is primarily due to the inherited limitations from the pre-trained 2D image diffusion models, which become more pronounced when it comes to 3D head avatars. In this work, we address these challenges by introducing a versatile coarse-to-fine pipeline dubbed HeadSculpt for crafting (i.e., generating and editing) 3D head avatars from textual prompts. Specifically, we first equip the diffusion model with 3D awareness by leveraging landmark-based control and a learned textual embedding representing the back view appearance of heads, enabling 3D-consistent head avatar generations. We further propose a novel identity-aware editing score distillation strategy to optimize a textured mesh with a high-resolution differentiable rendering technique. This enables identity preservation while following the editing instruction. We showcase HeadSculpt's superior fidelity and editing capabilities through comprehensive experiments and comparisons with existing methods.
3D Head Avatar Generation
HeadSculpt can create an assortment of head avatars, including humans (both celebrities and ordinary individuals) as well as non-human characters like superheroes, comic/game characters, paintings, and more.
 |
 |
 |
 |
 |
 |
| a DSLR portrait of Black Panther in Marvel | a DSLR portrait of Hulk | a DSLR portrait of Salvador Dalí | |||
 |
 |
 |
 |
 |
 |
| a head of Naruto Uzumaki | a portrait of Vincent van Gogh | a DSLR portrait of Lionel Messi | |||
 |
 |
 |
 |
 |
 |
| a DSLR portrait of Leo Tolstoy | a DSLR portrait of Kratos in God of War | a DSLR portrait of a female soldier, wearing a helmet | |||
 |
 |
 |
 |
 |
 |
| a head of Simpson in the Simpsons | a head of Terracotta Army | a DSLR portrait of a boy with facial painting | |||
3D Head Avatar Editing
In addition to head avatar creations, our method enables fine-grained editing, including local changes, shape/texture modifications, and style transfers.
 |
|
 |
 |
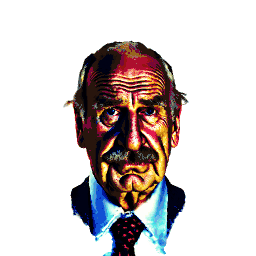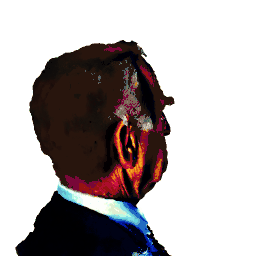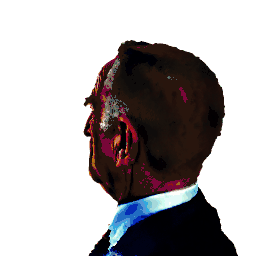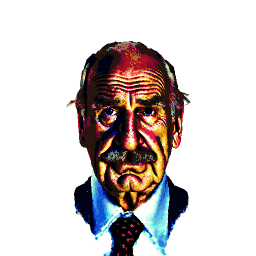 |
 |
| a DSLR portrait of Saul Goodman | turn him into a clown | make him older | |||
 |

|
 |
 |
 |
 |
| a DSLR portrait of Obama wearing a baseball cap | turn him into Pixar style | turn his face into a skull | |||
 |

|
 |
 |
 |
 |
| a DSLR portrait of Geralt in The Witcher 3 | make him simling | turn him into Minecraft | |||
 |

|
 |
 |
 |
 |
| a DSLR portrait of Audrey Hepburn | make her a claymation | make her color-restored | |||
 |

|
 |
 |
 |
 |
| a head of Caesar in Rise of the Planet of the Apes | make it carved out of wood | as a swimmer with a goggle | |||
Comparisons with Others
| Stable-DreamFusion | Latent-NeRF | 3DFuse | Fantasia3D.unofficial | HeadSculpt (Ours) |
 |
 |
 |
 |
 |
| a DSLR portrait of Batman | ||||
 |
 |
 |
 |
 |
| a DSLR portrait of Doctor Strange | ||||
 |
 |
 |
 |
 |
| a DSLR portrait of Two-face in DC | ||||
 |
 |
 |
 |
 |
| a DSLR portrait of Napoleon Bonaparte | ||||
Method
We craft high-resolution 3D head avatars in a coarse-to-fine manner. (a) We optimize neural field representations for the coarse model. (b) We refine or edit the model using the extracted 3D mesh and apply identity-aware editing score distillation if editing is the target. (c) The core of our pipeline is the prior-driven score distillation, which incorporates landmark control, enhanced view-dependent prompts, and an InstructPix2Pix branch.
